MySQL Replication的又一次尝试
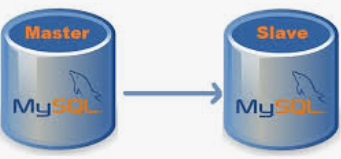
差不多有一年没写博客了,一直有心,但确实有点无力,今年的事情还真多了点,包括换新老板等大事让我的这个习以为常的工作类型和方式也改变了许多,不管咋样,接近年关,是应该写点啥记录一下了,还是一样,先水一篇技术的,然后再写什么年终总结。
随着手头的free host的增加,慢慢的发现自己居然有了三个Mysql的数据库服务器而且里面大大小小的数据库也有20多个,当然诸如这个博客,几个论坛,几个公司网站啥的基本都很小,但其他工具类网站例如zabbix的数据库就很大,备份起来比较麻烦,一直想想个办法集中一下,最近随着为幻兽帕鲁私服准备的小主机的上线,家里终于有个比较强悍的小主机可以招呼这些数据库了。
网上搜了一下Replication的文章,大多数都是讲的很简略,没发现跟我情况相符的,所以干脆放弃乱搜和想办法规避GPT类的幻觉,直接跳到Oracle的MySQL官方文档去看,这次还真的发现官方文档不错,编排的比较简洁清晰,但大多数的问题都照顾到了,看来还是背靠大树好乘凉啊,连文档的质量都提升了不少。
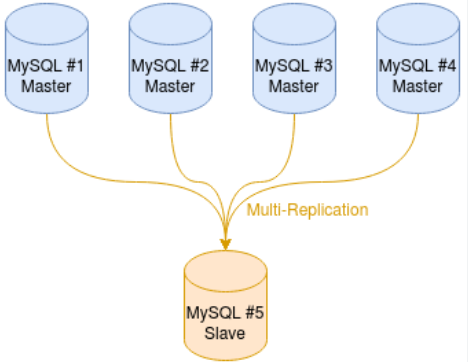
我的三台源MySQL服务器的版本都是8.04,但在不同的CPU上,两台ARM, 一台AMD,小主机上目标服务器上装的是MySQL的Docker,版本是8.4,这些差异会影响到后面的一些备份策略,不过从数据层面上讲没有任何不同,工具也基本做到了统一,所以还是挺满意的,本以为因为CPU和指令集带来的各种问题还真的没出现。
很多年前做过MySQL的replication,当时记得还是挺复杂的,这次多源到一个目标本来以为也会比较麻烦,但不知道是这些年自己的水平有些许的提升,还是产品已经更加成熟,各种坑都被填了,在几乎不到两个晚上的时间里就全部搞定了,没有那种需要自己编译才能解决的问题,基本都是调命令行或者脚本,最终就很顺利的同步了。下面就说一下详细的过程。
根据官方的文档,还是需要在源服务器上做相应的设置,我就按照我做的顺序,其实也是官方的顺序贴代码加上一些解释和绕坑的过程:
按照官方的说法必须先设服务器的server_id, 虽然这个id在后面没怎么用到,但我还是都给三台服务器设好了。
-- 检查Server_id
SELECT @@server_id as SERVER_ID;
show variables like 'server_id'
-- 设置server_id
SET GLOBAL server_id = 2; -- 系统默认的为1,所以从2开始按顺序设置,用啥都行,最大到256因为Replication是通过bin log来做的,所以检查一下源服务器的bin log的状态很重要:
-- 检查log_bin
show variables like 'log_bin';
-- 如果没有开启,就开启
SET GLOBAL log_bin = ON;源服务器做完之后,就要准备目标服务器,也是设置server_id就行:
-- 设置server_id
SET GLOBAL server_id = 10; 目标服务器的bin log可以不设置,但如果你还有其他的目标服务器把现在的这个目标服务器当源,那么就必须开,Mysql是支持那种 A>B>C>D的链式 replication的,虽然我没做过,但还是觉得很强大,接下来就是要在源服务器上开replication的账号了,可以用已有的,给replication和slave的权限就行,但新做一个一个账号管理起来很方便,而且这个账号的权限限制住对安全也有好处。这里注意,产生用户的时候要加with mysql_native_password,否则目标那边没办法用用户名和密码登录源服务器做同步。
-- 创建repl用户
CREATE USER 'yourusername'@'%' IDENTIFIED with mysql_native_password BY 'YourP@ssword';
GRANT REPLICATION SLAVE ON *.* TO 'yourusername'@'%';下面就要准备看一下这个同步的工作从bin log的什么位置开始,和这个位置前面的数据怎么传到目标服务器上,看了一大堆文档,还是放弃了从数据文件上下手的方法,毕竟要照顾各种不同的数据库引擎和格式,包括版本差异什么的,还是老老实实的回到mysqldump这个工具上直接输出sql吧,通用性强,安全可靠,主要是数据量不大,不过有三个数据库都是2G以上,这个简单,能删除的就删除,不能删除的就排除,总而言之,大过100M的数据都是机器产生的,不是我写出来的,所以不重要。
-- 获取复制源二进制日志坐标
FLUSH TABLES WITH READ LOCK;
-- 检查一下binlog文件和log pos状态:8.4版本以前的
SHOW MASTER STATUS;
-- 8.4的用这个
SHOW BINARY LOG STATUS;这里会得到两个非常重要的数据,一定要记下来,会在后面用到,一个是正在使用的binlog的文件名,一个是当前的位置,因为已经锁定了,所以这个位置在你解锁之前是不会变的,你就要用这两个数据让你的目标服务器知道从什么位置开始同步。
接下来就是用mysqldump开始备份数据库
mysqldump --databases db1 db2 --ignore-table=db1.bigsizetable1 --ignore-table=db2.bigsizetable2 > No2.dbMysqldump的选项很多,可以查官方文档根据自己的数据库的情况来有选择的备份,方式很灵活,也很稳定。备份完之后,马上释放 read lock
--每个服务器上释放read lock
UNLOCK TABLES;这样源数据库的工作就基本做完了,先要去目标服务器把原始数据导入进去,下载备份的数据文件,然后上传到目标服务器上,这里因为我的目标服务器的mysql是个docker,所以还要先把三个数据文件拷贝到Docker的volume里。
docker cp /root/No2.db YourDockerID:/
docker cp /root/No3.db YourDockerID:/
docker cp /root/No4.db YourDockerID:/接下来进入你的Docker的Bash
docker exec -it Yourdockername bash导入三个数据文件,当然你的三个服务器里的这些数据库不能重名,如果有重名,后面导入的会覆盖掉前面的,所以如果重名要现在源服务器里改名,当然,数据库支持的应用也要改配置文件。
mysql -uroot -p < No2.db
mysql -uroot -p < No3.db
mysql -uroot -p < No4.db这些工作做完之后就是要配置同步的环境和选项了,这里我因为是多源到单个目标,所以在配置时候要加上Channel,具体Channel的命名包括同步的线程数量等,大家去翻阅官方文档吧。
--创立多源replica设置,log file 和 log pos是从上面的命令 SHOW MASTER STATUS 中得到的
CHANGE REPLICATION SOURCE TO SOURCE_HOST="192.168.2.51", SOURCE_USER="yourusername", SOURCE_PASSWORD="YourP@ssword", SOURCE_LOG_FILE='binlog.001495', SOURCE_LOG_POS=19160140 FOR CHANNEL "source_1";
CHANGE REPLICATION SOURCE TO SOURCE_HOST="192.168.2.52", SOURCE_USER="yourusername", SOURCE_PASSWORD="YourP@ssword", SOURCE_LOG_FILE='binlog.001922', SOURCE_LOG_POS=122186 FOR CHANNEL "source_2";
CHANGE REPLICATION SOURCE TO SOURCE_HOST="192.168.2.53", SOURCE_USER="yourusername", SOURCE_PASSWORD="YourP@ssword", SOURCE_LOG_FILE='binlog.000023', SOURCE_LOG_POS=281628 FOR CHANNEL "source_3";然后就是设置过滤器来指定同步的时候什么数据库走什么Channel,里面有没有忽略的数据库,或者某个库里的表,选项支持白名单和黑名单,非常的灵活,但有一个诡异的地方是,某些地方需要用单引号,但某些必须不让用,这里让我困惑里很久才搞定
-- 这个就必须用单引号
CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE = ('db1.%','db2.%','db3.%') FOR CHANNEL "source_3";
-- 这个ignore table就不允许用单引号
CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE = (db1.bigsizetable1,db2.bigsizetable2) FOR CHANNEL "source_3";等确保你把你想要同步的数据库和表都包含进来之后,就可以用下面的命令开始同步:
-- 开始同步
START REPLICA;
-- 也可以停止同步
STOP REPLICA;同步以后可以用下面的命令检查状态:
SHOW REPLICA STATUS\G然后排除掉错误之后就发现所有的数据都开始同步了,接下来的用脚本在目标服务器把数据备份压缩,扔到备份服务器上,定期备份到线下的移动硬盘上就不是这篇博客的内容了,自此,所有的数据库的备份已经完成,完美。。。
慢着。。。我还有6,7个库在PostgreSQL上,要不要做replication呢??这是一个问题,让我好好想想。。





[…] 去年买了个Newif…
version 2.0 开始支持: 1.…
很多注册失败的总结的攻略:https:/…
[…] 之前的应用有俩是Wo…
[…] on line 73…